



NVIDIA GEFORCE RTX 2080 TI Scheda grafica |, ufficiale Nvidia RTX 2080 TI, 2080 e 2070 Specifiche, prezzo, data di rilascio | GAMERSNEXUS – PC da gioco Build e benchmark hardware
2080 TI Data di rilascio
Tuttavia, l’aspetto più grande di quella notizia è che l’interconnessione GPU coerente della cache proprietaria di Nvidia, NVLink, verrà alle carte di consumo. Le schede GeForce GTX implementeranno SLI su NVLink, con 2 canali NVLink in esecuzione tra ciascuna scheda. A una combinazione di 50 GB/sec di larghezza di banda full-duplex-il che significa che sono disponibili 50 GB di larghezza di banda in ogni direzione-questo è un importante aggiornamento sul precedente collegamento HB-SLI di Nvidia. Questo è in cima agli altri vantaggi di NVLink, in particolare la coerenza della cache. E tutto ciò arriva in un momento importante, poiché i requisiti di larghezza di banda inter-GPU continuano ad aumentare con ogni generazione.
Nvidia Geforce RTX 2080 TI Scheda grafica
Modded GeForce RTX 2080 TI supporta 22 GB di memoria GDDR6
Teclab rompe barriera all’orologio GPU 3GHz con GeForce RTX 2080 TI
Nvidia si dice che ritiri presto GeForce RTX 2080 (Ti/Super) e GeForce RTX 2070 (Super)
MSI outs GeForce RTX 2080 TI Gaming Z con memoria GDDR6 da 16 Gbps
Nvidia annuncia GeForce RTX 2080 TI “Cyberpunk 2077 Edition”
Asus mostra GeForce RTX 2080 Ti Rog Strix White Edition
Gigabyte lancia la scatola da gioco Aorus con RTX 2080 TI
Galax GeForce RTX 2080 Ti Hof 10th Anniversary Edition
MSI RTX 2080 TI Lightning 10th Anniversary Edition nella foto
MSI prende in giro GeForce RTX 2080 TI Lightning 10th Anniversary Edition
(PR) MSI Annuncia GeForce RTX 2080 TI Lightning Z
EVGA GEFORCE RTX 2080 TI Kingpin Edition è un ibrido
MSI GeForce RTX 2080 TI Lightning nella foto
Asus mette in mostra Rog GeForce RTX 2080 TI Matrix
Colorato geforce rtx 2080 ti igame kudan sorride per fotocamera
MSI prende in giro il geforce in fibra di carbonio RTX 2080 TI Lightning Z
Zotac GeForce RTX 2080 ti arcticstorm al debutto al CES 2019
MSI GeForce RTX 2080 TI Lightning Z PCB nella foto
Lavori colorati GeForce RTX 2080 (TI) RNG Edition con LCD a colori
(PR) Inno3D annuncia GeForce RTX Ichill Frostbite Series
EVGA prende in giro GeForce RTX 2080 TI Kingpin
Gigabyte che prepara GeForce rtx 2080 ti aorus turbo
NVIDIA Bundles Battlefield V con GeForce RTX gratuitamente
(PR) Manli annuncia GeForce RTX 2080 TI e 2070 con ventilatore da soffiante
Nuovo rapporto della scheda n. 21: RTX RGB Edition
Inno3d trasforma la carta GeForce RTX in gigantesco albero di Natale RGB
MSI annuncia GeForce RTX 2080 (TI) Sea Hawk (EK) X Series
Gigabyte prende in giro GeForce RTX 2080 (TI) scheda grafica Aorus
NVIDIA GEFORCE RTX 2080 TI & RTX 2080 ROUNDUP
TechPowerUp spiega la differenza tra le varianti di Turing A e non A GPU
NVIDIA GEFORCE RTX 2080 TI e RTX 2080 Performance “ufficiale”
Le nuove caratteristiche dell’architettura Nvidia Turing
NVIDIA Cambia GeForce RTX 2080 Recensioni Data al 19 settembre
NVIDIA GEFORCE RTX 2080 Recensioni Go Live il 17 settembre
EVGA svela i modelli Hydro Copper e Hybrid GeForce RTX
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GeForce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Data Center / Tesla
- Tegra
- Workstation / Quadro
- GeForce MX
- Titan RTX
- GeForce RTX 2080 TI
- GeForce RTX 2080 Super
- GeForce RTX 2080
- GeForce RTX 2070 Super
- GeForce RTX 2070
- GeForce RTX 2060 Super
- GeForce RTX 2060 12 GB
- GeForce RTX 2060
- GeForce MX250
- Impilamento 3D
- Accessori
- Annunci
- Mela
- BRACCIO
- Intelligenza artificiale
- Industria automobilistica
- Punti di riferimenti
- Affari e mercati
- Grafica cinese
- Concetti
- Connettività
- Creazione di contenuti
- Tecnologia di raffreddamento
- Criptovaluta
- Progetti personalizzati
- Offerte
- Display e monitor
- Eventi
- GPU e recinti esterni
- Recensioni esterne
- Overclock estremo
- Risultati finanziari
- Fonderie
- Pacchetti e offerte di gioco
- Requisiti di gioco
- Streaming di gioco
- Giochi
- Console di gioco
- Hardware da gioco
- Grafica
- API grafica
- Interviste
- Linux
- Tecnologia di memoria
- PC Mini/SFF/NUC
- Dispositivi mobili
- Modding
- Schede madri
- I Quaderni
- Brevetti e ricerche
- Casi per PC
- PCI Express
- Persone
- Riserve energetiche
- Sistemi predefiniti
- Risc-v
- Sicurezza
- Software e driver
- Magazzinaggio
- Super risoluzione
- Supercomputing (HPC)
- Codice video
- Storie virali
- Realta virtuale
- Raffreddamento ad acqua
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000 Mobile
- 2022 Radeon 7000
- 2021 Radeon 6000 Mobile
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000 Mobile
- 2017 Radeon 500
- 2017 Radeon 500 Mobile
- 2016 Radeon 400
- 2016 Radeon 400 Mobile
- 2015 Radeon 300
- 2015 Radeon 300 Mobile
- 2014 Radeon 200 Mobile
- 2013 Radeon 200
- Istinto di radeon
- Radeon Pro
- Blockchain Calcola
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GeForce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Data Center / Tesla
- Tegra
- Workstation / Quadro
- GeForce MX
- 2025 ARC DRUID TBA
- 2024 ARC Celestial TBA
- 2023 ARC BattleMage TBA
- 2022 ARC ALCHEMIST
- 2022 Intel Data Center HPC TBA
- 2021 Intel Data Center HP TBA
- 2020 Intel XE-LP
- Arc pro
2080 TI Data di rilascio
Specifiche ufficiali Nvidia RTX 2080, 2080 e 2070, prezzo, data di rilascio
Di Steve Burke pubblicato il 20 agosto 2018 alle 15:00

Aggiornamento: Aggiunta una correzione per i numeri core SM / CUDA, ora che sono stati trapelati i dettagli completi.
Nvidia ha annunciato oggi le sue nuove schede video Turing per i giochi, tra cui RTX 2080 TI, RTX 2080 e RTX 2070. Le carte vanno avanti con un’architettura Volta aggiornata ma familiare, con alcune modifiche all’SMS e alla memoria. La nuova nave RTX 2080 e 2080 TI con le carte di riferimento e le carte partner in gran parte allo stesso tempo (con alcuni modelli più avanzati in arrivo 1+ mese dopo), A seconda di quale partner è. I partner del consiglio di amministrazione non hanno ricevuto prezzi o addirittura denominazione delle carte fino allo stesso tempo dei media, quindi aspettati ritardi nelle soluzioni personalizzate. Si noti che inizialmente stavamo ascoltando una latenza di 1-3 mesi sulle carte partner, ma che sembra essere solo per modelli avanzati che stanno entrando proprio ora nella produzione. La maggior parte dei modelli di tri-fan dovrebbe essere disponibile nella stessa data.
Un altro importante punto di considerazione è la decisione di Nvidia di utilizzare una scheda di riferimento a doppia assiale, eliminando gran parte del valore delle carte partner alla fascia bassa. Allontanandosi dalle carte di riferimento del soffiatore e verso le carte dual-fan avranno immediatamente immediatamente partner del consiglio di amministrazione, qualcosa che potrebbe portare a una lenta gabine di Nvidia che espande le sue vendite dirette al consumatore e bypassing partner. La RTX 2080 TI avrà un prezzo di $ 1200 e verrà lanciato il 20 settembre, con il 2080 a $ 800 (e il 20 settembre) e il 2070 a $ 600 (data di rilascio di TBD).
NVIDIA RTX 2080 TI e 2080 Specifiche
Uno dei più grandi errori che le persone commettono quando si confrontano nuovi GPU è parlare di “Core Count.”Questo è errato per alcuni motivi, uno dei quali è che le prestazioni core-per-core non sono identiche ad architettura incrociata. Da Kepler a Pascal, ci sono stati guadagni fino al 30% per l’efficienza complessiva per le prestazioni per watt e semplicemente disegnare un confronto lineare tra i conteggi del core non lo soddisfa. Inoltre, i core Cuda non lo sono Veramente core, comunque: sono unità a punto galleggiante. Un SM sarebbe più simile a un nucleo per definizioni standard, che richiedono che un core sia in grado di recuperare e decodificare le istruzioni, eseguirle, leggere e scrivere dati da e verso registri e cache e risultati di calcolo. Le unità a punto mobile di Nvidia possono calcolare i risultati, ma non possono fare gran parte delle altre cose.
Il punto di dire tutto questo è che un rigoroso Pascal vs. Il confronto di Turing Core deve tenere conto delle differenze architettoniche che potrebbero cambiare il modo in cui si comporta un “core” per cominciare. La gente è caduta nella stessa trappola l’ultima volta.
NVIDIA RTX 2080 TI, 2080 e 2070 FOODERS EDIZIONE Specs
Nuove unità di punta mobile RTX 2080 TI di NVIDIA, con le unità di punta mobile, con le FPU non TI Hosting RTX 2080. Nvidia si attacca a 64 FPU per multiprocessore di streaming, che avrebbe messo il 2080 TI a 68 SMS, con il 2080 a 46 SMS. Nvidia ha rielaborato l’architettura SM per questa GPU, quindi non siamo ancora positivi su tutti i dettagli più fini.
Le nuove GPU passano anche a GDDR6, un turno previsto. Al momento, GDDR6 esegue circa un costo bom del 20% superiore a GDDR5, ma quel costo diminuirà nel tempo. GDDR6 consente minimo 14 Gbps per throughput del pin su RTX 2080 e 2080 TI, una spinta degna di nota su 8 Gbps e 10 Gbps sulle generazioni precedenti. GDDR6 può anche spingere fino a 16 Gbps per pin, ma non vi è alcuna promessa immediata per le nuove GPU. Non siamo ancora sicuri sull’impatto del tempismo della memoria di GDDR6. Il 2080 TI ospiterà 11 GB di GDDR6 su un bus di memoria da 352 bit, con larghezza di banda di memoria nel quartiere di 620 GB/s. RTX 2080 ospiterà 8 GB di GDDR6 su un’interfaccia a 256 bit e quindi consentirà una larghezza di banda di memoria 448 GB/s.
| RTX 2080 Ti | RTX 2080 | RTX 2070 | |
| FPUS FP32 (“Cuda Cores”) | 4352 | 2944 | 2304 |
| Streaming multiprocessori | 68 | 46 | 36 |
| Orologio core / Boost Orologio | 1350/1545 Fe: 1635MHz | 1515/1710 Fe: 1800MHz | 1410/1620 Fe: 1710MHz |
| Interfaccia di memoria | 352-bit | 256-bit | 256-bit |
| Capacità di memoria | 11 GB | 8 GB | 8 GB |
| Velocità GDDR6 | 14 Gbps | 14 Gbps | 14 Gbps |
| Banda di memoria | 616 GB/s | 448 GB/s | 448 GB/s |
| Sli | Nvlink 2 vie | Nvlink 2 vie | TBD |
| TDP | ~ 265 ~ 285W | ~ 250-260W | 175-185W |
| Prezzo | $ 1,200 O $ 1000* | $ 800 O $ 700* | $ 600 O $ 500* |
| Data di rilascio | Settembre. 20, 2018 | Settembre. 20, 2018 | TBD |
*Fonte per i prezzi: sito web di Nvidia. NOTA: Abbiamo anche sentito che i prezzi (forse per le carte non FE? O c’è solo una cattiva comunicazione all’interno di Nvidia?) potrebbe anche essere $ 500 per il 1070, $ 700 per il 2080 e $ 1000 per il 2080 Ti. Pensiamo che questo potrebbe essere Fe vs. Riferimento, ma potrebbe anche essere una cattiva comunicazione da parte delle squadre di Nvidia. Non è chiaro al momento.
Nvidia annuncia la serie GeForce RTX 20: RTX 2080 TI e 2080 a settembre. 20, RTX 2070 in ottobre

Il keynote GamesCom 2018 di Nvidia è appena concluso, e come molti si aspettano da quando è stato annunciato il mese scorso, Nvidia si sta preparando a lanciare la loro prossima generazione di hardware GeForce. Annunciato all’evento e in vendita a partire dal 20 settembre è la serie GeForce RTX 20 di Nvidia, che sta succedendo all’attuale serie GeForce GTX 10. Sulla base della nuova architettura GPU Turing di Nvidia e basato sul processo “FFN” da 12nm di TSMC, Nvidia ha obiettivi alti, cercando di guidare un intero turno di paradigma nel modo in cui i giochi sono resi e come vengono valutate le schede video PC. Il CEO Jensen Huang ha definito l’architettura GPU più importante di Turing Nvidia dalla Tesla GPU Architecture (GPU G80) del 2006, e dal punto di vista delle caratteristiche è chiaro che non sta esagerando le questioni.
Come tradizionalmente, le prime carte dalla stalla Nvidia sono le carte di fascia alta. Ma in una pausa piuttosto considerevole dalla tradizione non solo otterremo le carte X80 e X70 al momento del lancio, ma anche la scheda X80 Ti. Significa il GeForce RTX 2080 TI, RTX 2080 e RTX 2070 colpiranno tutti le strade entro un mese l’una dall’altra. Lo stack di prodotti di Nvidia rimane invariato qui, quindi RTX 2080 TI rimane la loro carta di punta, mentre RTX 2080 è la loro carta di fascia alta, e quindi RTX 2070 la carta leggermente più economica per attirare gli appassionati senza rompere la banca.
Tutte e tre le carte verranno lanciate nei prossimi due mesi. Prima di tutto saranno RTX 2080 Ti e RTX 2080, che verranno lanciati il 20 settembre . La RTX 2080 TI inizierà a $ 999 per le carte partner, mentre RTX 2080 inizierà a $ 699. Nel frattempo la RTX 2070 verrà lanciata ad un certo punto in ottobre, con le carte partner a partire da $ 499. Su base storica, tutti questi prezzi sono più alti dell’ultima generazione di ovunque tra $ 120 e $ 300. Nel frattempo, le carte dei fondatori della qualità di riferimento di NVIDIA sono di nuovo indietro e queste porteranno un premio da $ 100 a $ 200 rispetto ai prezzi di base.
Sfortunatamente, Nvidia sta già prendendo preordini qui, quindi i consumatori sono essenzialmente tenuti a fare un “acquisto cieco” se vogliono afferrare una carta dal primo lotto. Nvidia ha offerto sorprendentemente poche informazioni sulle prestazioni e suggeriamo di aspettare recensioni di terze parti affidabili (i.e. Us), tuttavia devo ammettere che non immagino che ci saranno molte scorte disponibili quando le recensioni di Time colpiscono per le strade.
| Confronto delle specifiche di nvidia geforce | ||||||
| RTX 2080 Ti | RTX 2080 | RTX 2070 | GTX 1080 | |||
| Cuda core | 4352 | 2944 | 2304 | 2560 | ||
| Orologio principale | 1350MHz | 1515MHz | 1410MHz | 1607MHz | ||
| Aumenta l’orologio | 1545MHz | 1710MHz | 1620 MHz | 1733MHz | ||
| Orologio di memoria | 14 Gbps GDDR6 | 14 Gbps GDDR6 | 14 Gbps GDDR6 | 10 Gbps GDDR5X | ||
| Larghezza del bus di memoria | 352-bit | 256-bit | 256-bit | 256-bit | ||
| Vram | 11 GB | 8 GB | 8 GB | 8 GB | ||
| Perf di precisione singola. | 13.4 tflops | 10.1 tflops | 7.5 tflops | 8.9 tflops | ||
| Tensore perf. | 440t OPS (Int4) | ? | ? | N / A | ||
| Ray Perf. | 10 grigi/s | 8 grigi/s | 6 grigi/s | N / A | ||
| “RTX-OPS” | 78T | 60T | 45T | N / A | ||
| TDP | 250 W | 215W | 175w | 180 W | ||
| GPU | Big Turing | Turing senza nome | Turing senza nome | GP104 | ||
| Conteggio dei transistor | 18.6b | ? | ? | 7.2b | ||
| Architettura | Turing | Turing | Turing | Pascal | ||
| Processo di fabbricazione | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 16nm | ||
| Ora di pranzo | 20/09/2018 | 20/09/2018 | 10/2018 | 27/05/2016 | ||
| Prezzo di lancio | MSRP: $ 999 Fondatori $ 1199 | MSRP: $ 699 Fondatori $ 799 | MSRP: $ 499 Fondatori $ 599 | MSRP: $ 599 Fondatori $ 699 | ||
Nvidia’s Turing Architecture: RT & Tensor Core
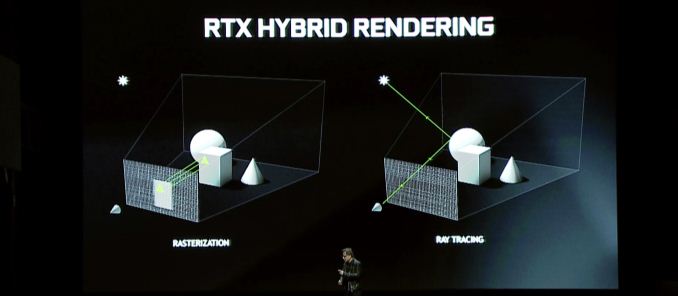
Allora cosa porta Turing al tavolo? La caratteristica del tendone su tutta la linea è il rendering ibrido, che combina la traccia di Ray con la tradizionale rasterizzazione per sfruttare i punti di forza di entrambe le tecnologie. Questo annuncio è essenzialmente una continuazione dell’annuncio RTX di Nvidia all’inizio di quest’anno, quindi se hai pensato che l’annuncio fosse un po ‘scarso, beh, allora ecco il resto della storia.
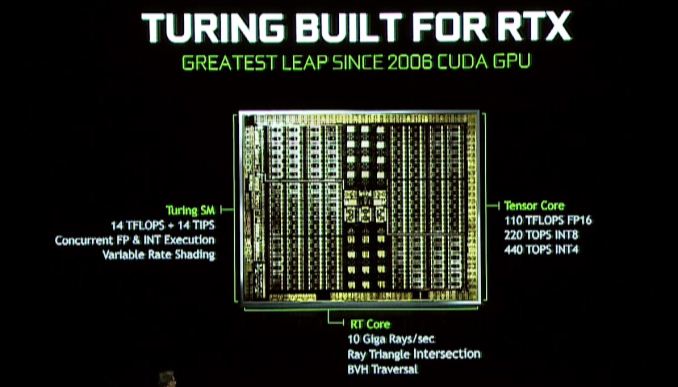
Il grande cambiamento qui è che Nvidia includerà ancora più hardware di tracciamento dei raggi con Turing per offrire un’accelerazione più rapida ed efficiente. Novità dell’architettura Turing è ciò che Nvidia sta chiamando un core RT, le cui basi su cui non siamo pienamente informati in questo momento, ma fungono da processori dedicati di tracciamento dei raggi. Questi blocchi del processore accelerano entrambi i controlli di intersezione del triangolo ray e la manipolazione della gerarchia del volume (BVH), essendo quest’ultima una struttura di dati molto popolare per archiviare oggetti per la traccia di raggi.
Nvidia afferma che la parte di GeForce RTX più veloce può lanciare 10 miliardi di raggi al secondo, che rispetto al Pascal non accelerato è un miglioramento 25x nelle prestazioni di tracciamento dei raggi.
L’architettura Turing trasporta anche i nuclei di tensori da Volta, e in effetti questi sono stati persino migliorati su Volta. I nuclei tensori sono un aspetto importante di più iniziative Nvidia. Insieme ad accelerare i raggi che si rintracciano, l’altro strumento di Nvidia nella loro borsa di trucchi Turing è quello di ridurre la quantità di raggi richiesti in una scena usando l’IA denoising per ripulire un’immagine, che è qualcosa che i nuclei di tensore eccellono. Ovviamente non è l’unica caratteristica per i core tensori per – l’intero impero di rete AI/neurale di Nvidia è quasi costruito su di essi – quindi sebbene non sia un obiettivo principale per la folla di Gamescom, ciò conferma anche che l’hardware di rete neurale più potente di Nvidia arriverà a una gamma più ampia di GPU.
Guardando il rendering ibrido in generale, è interessante che, nonostante questi acceleramenti individuali, le promesse complessive di Nvidia non sono altrettanto estreme. Tutto sommato, la società promette un aumento delle prestazioni 6x rispetto a Pascal, e questo non specifica da quali parti. Il tempo dirà se anche questa è una valutazione realistica, poiché anche con i core RT, il trappola dei raggi in generale è ancora piuttosto il maiale delle risorse.
Per quanto riguarda le questioni di gioco in particolare, i benefici del rendering ibrido sono potenzialmente significativi, ma dipenderà fortemente da come gli sviluppatori scelgono di usarlo. Dal punto di vista delle prestazioni non sono sicuro che ci sia molto da dire qui, ed è perché Ray Tracing & Hybrid Rendering sono in definitiva caratteristiche per migliorare la qualità del rendering, non migliorare le prestazioni degli algoritmi di oggi. Concesso, se avessi provato a fare tracce di raggi sulle GPU di oggi sarebbe estremamente lento – e di conseguenza un incredibile accelerato – ma nessuno usa i sistemi di tracciamento del percorso lento sull’hardware corrente per questo motivo. Quindi il rendering ibrido riguarda invece la sostituzione delle approssimazioni e degli hack dell’attuale tecnologia di rasterizzazione con metodi di rendering più accurati. In altre parole, meno “fingerlo” e più “facendolo.”

Questi vantaggi di qualità, a loro volta, sono in genere raggruppati su illuminazione, ombre e riflessi. Tutte e tre le caratteristiche si basano intrinsecamente sulle proprietà della luce, che in termini semplicistiche si muovono come raggio e che fino ad ora vari algoritmi hanno fingo di fingere in anticipo le scene “pre-cottura”. E mentre gli algoritmi attuali sono abbastanza buoni, non sono ancora vicini a accurati. Quindi c’è spazio chiaro per il miglioramento.


Nvidia da parte loro sta particolarmente lanciando l’illuminazione globale, che è uno dei compiti più difficili. Tuttavia ci sono anche altri metodi di illuminazione che beneficiano, per non parlare dei riflessi e delle ombre di quegli oggetti illuminati. E in verità è qui che le parole sono uno strumento scarso; È difficile descrivere come un’ombra rintracciata di raggio sembra migliore di un’ombra falsa con PCSS o illuminazione in tempo reale sopra l’illuminazione pre-cotta. Questo è il motivo per cui Nvidia, la società di schede video, spingerà gli aspetti visivi di tutto questo più difficile che mai.
Nel complesso, quindi, il rendering ibrido è la funzione Lynchpin della serie GeForce RTX 20. Seguendo le loro presentazioni Gamescom e Siggraph, è chiaro che Nvidia ha investito pesantemente sul campo e che hanno scommesso il successo del marchio GeForce nei prossimi anni su questa tecnologia. I nuclei RT e i core tensori sono hardware di funzione semi-fissa; Non possono essere utilizzati per la rasterizzazione e i transistor assegnati ad essi sono transistor che avrebbero potuto essere dedicati a un hardware più rastizativo altrimenti. Quindi Nvidia ha fatto una mossa incredibilmente significativa qui in termini di costi di opportunità percorrendo il percorso di rendering ibrido piuttosto che costruire un Pascal più grande.
Di conseguenza, Nvidia sta tentando un cambio di paradigma nel rendering dei consumatori, uno che abbiamo visto solo prima con l’introduzione di shader pixel e vertex (DX8 e DX9 ERA Tech) nel 2001 e 2002. Questo è il motivo per cui l’iniziativa DirectX RayTracing (DXR) di Microsoft è così importante, così come lo sono gli altri sviluppatori e le iniziative dei consumatori di Nvidia. Nvidia deve vendere consumatori e sviluppatori su questa visione di miscelare la rasterizzazione con il tracing di Ray per fornire una migliore qualità dell’immagine. E più di questo, devono facilitare gli sviluppatori nell’idea di lavorare con unità di funzione più specializzate e fisse poiché la legge di Moore continua a rallentare e hardware di funzione fissa diventa un mezzo per ottenere una maggiore efficienza.
Nvidia non ha scommesso la fattoria sul rendering ibrido, ma non hanno mai tentato di spostare il mercato in questo modo. Quindi, se sembra che Nvidia sia iper-focalizzato sul rendering ibrido e sul ray tracing, è perché lo sono. È la loro visione del futuro, e ora devono coinvolgere tutti gli altri.
Turing SM: core int dedicati, cache unificata, ombreggiatura a velocità variabile
O. In particolare qui, sta ereditando uno dei cambiamenti più nuovi di Volta, che hanno visto i core interi separati nei loro blocchi, invece di essere un aspetto dei nuclei di cuda in virgola mobile. Il vantaggio qui – almeno per quanto abbiamo visto in Volta – è che accelera la generazione di indirizzi e fuso Multiply Aggiungi prestazioni (FMA), sebbene per molti aspetti di Turing, probabilmente c’è di più (e ciò che può essere abituato) di quanto stiamo vedendo oggi.
Turing SM include anche ciò che Nvidia sta chiamando un’architettura di cache unificata.”Dato che sto ancora aspettando i diagrammi SM ufficiali di Nvidia, non è chiaro se questo è lo stesso tipo di unificazione che abbiamo visto con Volta – in cui la cache L1 è stata unita alla memoria condivisa – o se Nvidia ha fatto un ulteriore passo avanti. Ad ogni modo Nvidia sta dicendo che offre il doppio della larghezza di banda della “generazione precedente” che non è chiaro se nvidia significa Pascal o Volta (con quest’ultimo più probabile).
Infine, nascosto anche nel comunicato stampa di Siggraph Turing è la menzione del supporto per l’ombreggiatura a velocità variabile. Questa è una tecnica di rendering grafica relativamente giovane e imminente di cui esistono informazioni limitate (soprattutto per quanto esattamente Nvidia lo sta implementando). Ma a un livello molto elevato sembra la prossima generazione della tecnologia di ombreggiatura multi-Res di Nvidia, che consente agli sviluppatori di rendere diverse aree di uno schermo in varie risoluzioni efficaci, al fine di concentrare la qualità (e il tempo di rendering) nelle aree in cui È il più vantaggioso.
Nutrire la bestia: supporto GDDR6
Poiché la memoria utilizzata dalle GPU è sviluppata da aziende esterne, non ci sono grandi segreti qui. Il JEDEC e i suoi grandi 3 membri Samsung, SK Hynix e Micron hanno sviluppato tutti la memoria GDDR6 come successore di GDDR5 e GDDR5X e Nvidia ha confermato che Turing lo supporterà. A seconda del produttore, la GDDR6 di prima generazione è generalmente promossa come offrendo fino a 16 Gbps per pin di larghezza di banda della memoria, che è 2x a quella delle carte GDDR5 di tarda generazione di Nvidia e il 40% più veloce.
| GPU Memory Math: GDDR6 vs. HBM2 vs. GDDR5X | ||||||||
| NVIDIA GEFORCE RTX 2080 TI (GDDR6) | NVIDIA GEFORCE RTX 2080 (GDDR6) | Nvidia Titan v (HBM2) | Nvidia Titan XP | NVIDIA GEFORCE GTX 1080 TI | NVIDIA GEFORCE GTX 1080 | |||
| Capacità totale | 11 GB | 8 GB | 12 GB | 12 GB | 11 GB | 8 GB | ||
| B/p per pin | 14 GB/s | 1.7 GB/s | 11.4 Gbps | 11 Gbps | ||||
| Capacità di chip | 1 GB (8 GB) | 4 GB (32 GB) | 1 GB (8 GB) | |||||
| NO. Patatine/kgsd | 11 | 8 | 3 | 12 | 11 | 8 | ||
| B/n per chip/stack | 56 GB/s | 217.6 gb/s | 45.6 gb/s | 44 GB/s | ||||
| Larghezza del bus | 352-bit | 256-bit | 3092-bit | 384-bit | 352-bit | 256-bit | ||
| Totale b/n | 616 GB/s | 448 GB/s | 652.8 GB/s | 547.7 GB/s | 484 GB/s | 352 GB/s | ||
| Tensione DRAM | 1.35 v | 1.2 V (?) | 1.35 v | |||||
Rispetto a GDDR5X, GDDR6 non è così grande come alcune generazioni di memoria del passato, poiché molte delle innovazioni di GDDR6 erano già cotte in GDDR5X. Tuttavia, insieme a HBM2 per casi d’uso di fascia alta, si prevede che diventerà la memoria della spina dorsale del settore GPU. I cambiamenti principali qui includono tensioni operative inferiori (1.35v) e internamente la memoria è ora divisa in due canali di memoria per chip. Per un chip standard a 32 bit, questo significa una coppia di canali di memoria a 16 bit, per un totale di 16 di questi canali su una scheda da 256 bit. Mentre questo a sua volta significa che esiste un numero molto elevato di canali, anche le GPU sono ben posizionate per trarne vantaggio poiché sono enormi dispositivi paralleli per cominciare.

Nvidia per la loro parte ha confermato che le prime carte GeForce RTX eseguiranno il loro GDDR6 a 14 Gbps, che sembra essere il voto più veloce offerto da tutti i Big 3 Members. Sappiamo che Nvidia utilizza esclusivamente GDDR6 di Samsung per le loro carte Quadro RTX – presumibilmente perché hanno bisogno della densità – tuttavia per le schede GeForce RTX il campo dovrebbe essere aperto a tutti i produttori di memoria. Anche se a lungo termine, questo lascia due strade aperte a schede di capacità più elevata: spostarsi fino a chip di densità da 16 GB o andare a conchiglia con i chip da 8 GB che stanno usando ora.
Odds & Ends: NVLink SLI, Virtuallink e 8K HEVC
Sebbene ciò non sia stato menzionato nella stessa presentazione di Gamescom di Nvidia, il sito Web della serie 20 di Nvidia di GeForce 20 conferma che SLI sarà di nuovo disponibile per alcune carte GeForce RTX di fascia alta. In particolare, sia RTX 2080 Ti che RTX 2080 supporteranno SLI. Nel frattempo l’RTX 2070 non supporterà SLI; questo è un allontanamento dal 1070 che lo ha offerto.
Tuttavia, l’aspetto più grande di quella notizia è che l’interconnessione GPU coerente della cache proprietaria di Nvidia, NVLink, verrà alle carte di consumo. Le schede GeForce GTX implementeranno SLI su NVLink, con 2 canali NVLink in esecuzione tra ciascuna scheda. A una combinazione di 50 GB/sec di larghezza di banda full-duplex-il che significa che sono disponibili 50 GB di larghezza di banda in ogni direzione-questo è un importante aggiornamento sul precedente collegamento HB-SLI di Nvidia. Questo è in cima agli altri vantaggi di NVLink, in particolare la coerenza della cache. E tutto ciò arriva in un momento importante, poiché i requisiti di larghezza di banda inter-GPU continuano ad aumentare con ogni generazione.

Ora la grande domanda è se questo invertirà il continuo declino della SLI, e al momento sto adottando un approccio un po ‘pessimistico, ma sono ansioso di sentire di più da Nvidia. 50 GB/SEC è un grande miglioramento rispetto a HB-SLI, tuttavia è ancora solo una frazione della larghezza di banda della memoria locale a 448 GB (o più) di memoria disponibile per una GPU. Quindi da solo non risolve i problemi che hanno ostinatamente rendering multi-GPU, né con sincronizzazione AFR o una divisione efficace del carico di lavoro. A tale proposito, probabilmente sta dicendo che Nvidia non supporta NvLink SLI su RTX 2070.
Nel frattempo i giocatori qualcosa di nuovo non vede l’ora di VR, con l’aggiunta del supporto Virtuallink. La modalità alternativa di tipo C USB è stata annunciata il mese scorso e supporta 15 W+ di potenza, 10 Gbps di USB 3.1 Dati Gen 2 e 4 corsie del video Displayport HBR3 su un singolo cavo. In altre parole, è un Displayport 1.4 Connessione con dati e potenza extra che intende consentire a una scheda video di guidare direttamente un auricolare VR. Lo standard è supportato da Nvidia, AMD, Oculus, Valve e Microsoft, quindi le carte GeForce RTX saranno le prime di ciò che ci aspettiamo sarà in definitiva una serie di prodotti a supporto dello standard.
| Modie alternative di tipo C USB | ||||||
| Virtuallink | DisplayPort (4 corsie) | DisplayPort (2 corsie) | Base USB-C | |||
| Larghezza di banda video (RAW) | 32.4 Gbps | 32.4 Gbps | 16.2 Gbps | N / A | ||
| USB 3.X Data Larghezza di banda | 10 Gbps | N / A | 10 Gbps | 10 Gbps + 10 Gbps | ||
| Coppie di corsie ad alta velocità | 6 | 4 | ||||
| Massima potenza | Obbligatorio: 15w Opzionale: 27w | Opzionale: fino a 100W | ||||
Infine, mentre Nvidia ha toccato solo brevemente l’argomento, sappiamo che il loro blocco di codificatore video, Nvenc, è stato aggiornato per Turing. L’ultima iterazione di Nvenc aggiunge specificamente il supporto per la codifica HEVC 8K. Nel frattempo Nvidia è stato anche in grado di sintonizzare ulteriormente la qualità del loro encoder, consentendo loro di ottenere una qualità simile a quella prima con un bitrate video inferiore del 25%.